 Comment convertir un article saisi en .tex vers un traitement de textes
Comment convertir un article saisi en .tex vers un traitement de textesDans le document simple que j’attache à la fin de cet article, on trouvera la plupart des commandes que l’on utilise dans un article : citations, notes de bas de page, bibliographie. On trouvera aussi des mots en grec ancien, et même en arabe. Le but est de montrer comment on peut travailler entièrement sous XeLaTeX, puis convertir l’article au dernier moment dans le format .odt pour le donner à l’éditeur.
Le préambule du document .tex
Il doit être aussi simple que possible pour une raison évidente : les raffinements typographiques et de mise en page sont réservés à (Xe)LaTeX lui-même. Le fichier de traitement de texte devra être propre, et répondre aux exigences de base de l’éditeur, qui le reprendra de toute façon dans son propre système de mise en page.
On peut donc partir de ceci :
\documentclass{article}
% J'aime bien toujours charger babel dont la typographie est bien
% meilleure que celle de polyglossia. Mais si vous le souhaitez,
% ou si vous en avez besoin, vous pouvez toujours mettre:
% \usepackage{polyglossia}
% \setdefaultlanguage{french}
\usepackage[french]{babel}
\usepackage{fontspec,xltxtra}
\setmainfont{Linux Libertine O}
\setsansfont{Linux Biolinum O}
\setmonofont[Scale=.9]{Linux Libertine Mono O}
\usepackage{csquotes}
\title{<titre du document>}
\author{<nom de l'auteur>}À vrai dire, on peut se contenter de :
\documentclass{article}
\usepackage{fontspec,xltxtra}
\title{<titre du document>}
\author{<nom de l'auteur>}car par défaut, pandoc ignorera les paramètres de langue et les polices de caractère. Le plus simple sera de choisir ces éléments dans les paramètres du document de traitement de texte, comme nous le verrons à la fin de cet article. J’ai cependant ajouté ces lignes dans le préambule du source .tex, car on peut souhaiter compiler le document plusieurs fois avant de le passer sous traitement de texte.
Auquel cas, une solution est de créer deux préambules : l’un pour LaTeX, l’autre pour pandoc. On les écrira dans deux fichiers distincts qu’on inclura au cas par cas.
Les commandes courantes
Quels sont les éléments couramment utilsés dans un article ? On peut penser à ceci :
- un résumé :
\begin{abstract} \end{abstract} - des commandes de division de texte :
\section{}, \subsection{}, \paragraph{}, etc. - des notes de bas de page :
\footnote{} - des citations :
\begin{quote} \end{quote} - des citations en vers :
\begin{verse} \end{verse} - des commandes de mise en forme des mots
\emph{}, \textbf{}
Tout cela est parfaitement pris en charge par pandoc.
Tableaux
Les tableaux sont également pris en charge, mais les extensions telles que longtable ne le sont pas. Si le document comporte des tableaux longs, on les saisira néanmoins dans l’environnement standard tabular. Sous (Xe)LaTeX, les résultats ne seront pas bons, mais les tableaux seront correctement convertis sous traitement de texte.
Si on utilise longtable sans utiliser de type de colonnes personnalisé, une solution peut être de mettre dans le préambule spécifique à pandoc les lignes suivantes :
\let\longtable\tabular
\let\endlongtable\endtabularCe qui permettra d’utiliser longtable lorsqu’on utilise (Xe)LaTeX.
Langues étrangères
La seule contrainte est de les saisir en unicode : tous les caractères seront convertis, et même les langues qui se lisent de droite à gauche, comme l’arabe, seront reconnues. Si les textes en langue étrangère sont saisis dans des commandes telles que \textgreek{} pour le grec ou \textarab{} pour l’arabe, peu importe : les commandes seront le plus souvent ignorées.
Dans certains cas cependant, les commandes de changement de langue propres polyglossia produisent des effets inattendus : on a ainsi constaté en faisant des tests que des commandes telles que \textfrench{} ou \textlatin{} ne produisaient rien ! Les textes passés en argument disparaissent tout simplement !
Dans ce cas, il faut neutraliser ces commandes dans le préambule, de la façon suivante (l’exemple qui suit neutralise les deux commandes données au paragraphe précédent) :
\renewcommand{\textfrench}[1]{#1}
\renewcommand{\textlatin}[1]{#1}En fonction des commandes à neutraliser, on adaptera ce code, qu’il faut évidemment placer dans le préambule après celles qui ont servi à charger polyglossia ou tout autre package dans lequel ces commandes sont définies.
Bibliographie
On prend ici le cas d’une bibliographie construite à l’aide de biblatex/biber. Le plus important est de comprendre que pandoc ignore les styles de citation et les styles de bibliographie que l’on a choisis dans le source .tex. À la place, pandoc peut utiliser tout style au format CSL. Il en exixte un très grand nombre (voir ci-dessous).
Dans le document, on peut utiliser les commandes de citation suivantes :
-
\cite{} -
\autocite{} -
\citeyear{} -
\parencite{} -
\footcite{} -
\textcite[avant][après]{} -
\smartcite[avant][après]{} -
\autocite{} -
\citeauthor{}
Et à la fin du document, on mettra simplement \printbibliography. Les bibliographies multiples ne sont pas prises en charge.
Conversion du document
La conversion se fait à la ligne de commande.
Pour un document sans bibliographie, on fait ceci :
pandoc --latex-engine=xelatex article.tex -o article.odtPour un document avec bibliographie, on a deux possibilités.
1 Choix par défaut du style Chicago author-date :
pandoc --bibliography="bibliographie.bib" --biblatex \
--latex-engine=xelatex article.tex -o article.odtCette commande convertit le fichier article.tex vers article.odt, en utilisant pour les citations le fichier bibliographie.bib.
2 Choix d’un style CSL. Dans cet exemple, j’utilise le style « harvard-kings-college-london » :
pandoc --filter pandoc-citeproc --csl=harvard-kings-college-london.csl \
--bibliography="bibliographie.bib" --biblatex \
--latex-engine=xelatex article.tex -o article.odtPour récupérer un style existant, on peut se rendre ici : https://www.zotero.org/styles. Le dépôt Git est ici : https://github.com/citation-style-language/styles.
Il faut enregistrer le fichier CSL au même endroit que les fichiers .tex et .bib.
Post-traitement
Observez bien le fichier de sortie. Vous remarquerez qu’il est bien stylé. Il sera alors très facile de générer une table des matières.
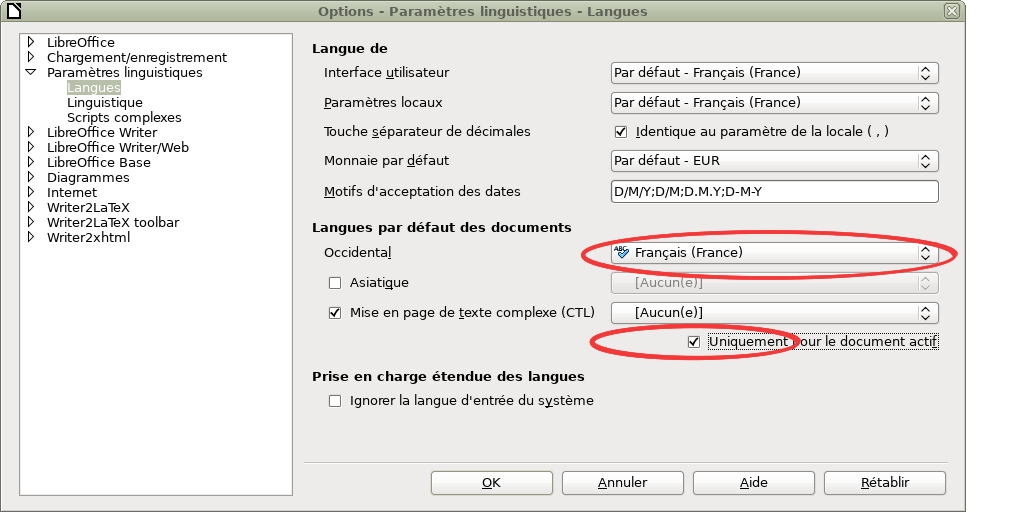
En ce qui concerne les langues à caractères non-occidentaux, comme le grec ou l’arabe, il suffit encore de modifier les paramètres du document LibreOffice pour que tout soit adapté parfaitement sur l’ensemble du document. Dans le document LibreOffice attaché, voici comment j’ai procédé :
Langue française
Typographie
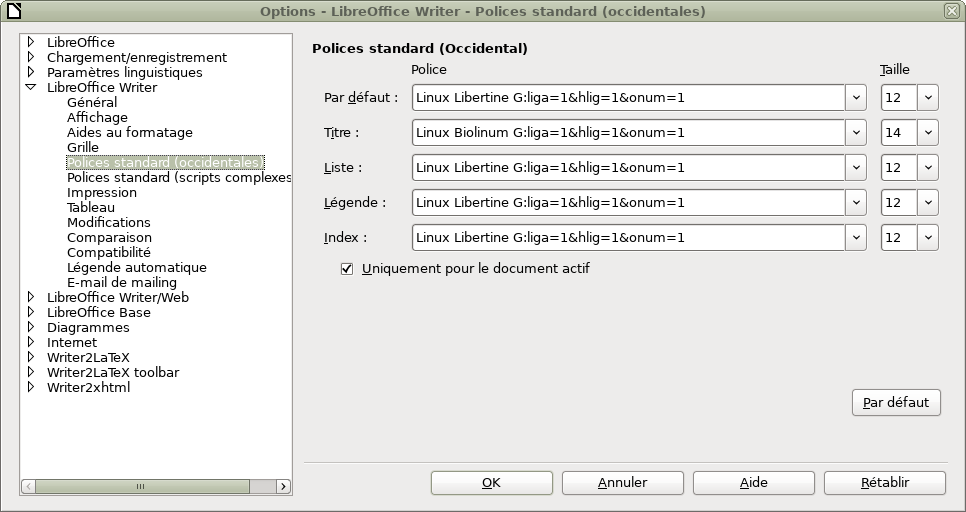
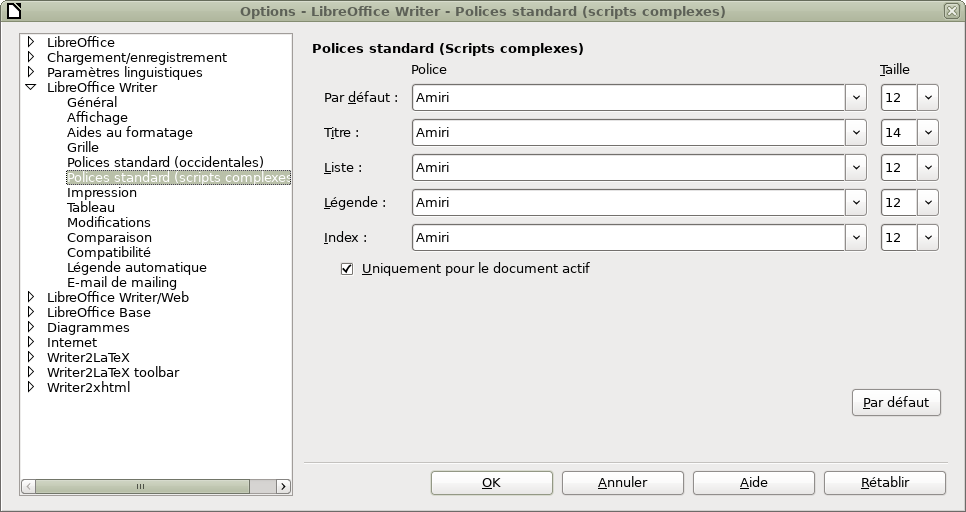
Remarquez que l’utilisation des features OpenType dans les paramètres dits des « Polices standard (occidentales) » a pour effet d’insérer automatiquement des espaces fines entre les mots et tout signe de ponctuation double.
Fichiers
Voici les fichiers que j’ai utilisés. Ils vous permettront de vous entraîner !


Vos commentaires
# Le 13 février 2015 à 13:10, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Les limites encore à tester : les types persos. A voir si on peut imaginer des choses comme un script de conversion ou autre.
ledmac/ledpar ->surcharger les commandes.
# Le 13 février 2015 à 20:45, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Ou encore un package avec une option pandoc/nopandoc, voire une classe de document spécifique.
# Le 13 février 2015 à 21:01, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
je pense pas que la classe de doc soit une bonne solution. Un package avec option, oui pourquoi pas. mais enfin l’option nopandoc, cela revient à ne pas activer le package non ?
# Le 13 février 2015 à 21:05, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
a tout hasard, je me suis amusé à créer une classe bidon, avec juste
, donc qui ne définit pas
\section. Il transforme bien les\sectionen titre de niveau 1. Donc c’est qu’il ne va pas jusqu’au fond de la moulinette LaTeX ;-)# Le 14 février 2015 à 08:32, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
L’option nopandoc reviendrait en effet à désactiver le package, tout en laissant la ligne présente dans le préambule, tandis que l’option pandoc (activée par défaut) redéfinirait un certain nombre de commandes. Ce serait une façon de ne pas avoir à écrire deux préambules. Mais est-ce vraiment utile ? Je n’en suis pas sûr, car la conversion vers un format de traitement de texte est une opération unique, typiquement faite pour les besoins d’un éditeur qui réclame ce format... Le test fait à partir d’une classe qui ne définit pas
\section{}montre que pandoc interprète ces commandes de façon indépendante de toute classe de document. Même chose, semble-t-il, pour la bibliographie...# Le 14 février 2015 à 13:20, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
oui, enfin il faudrait écrire deux préambule en changeant ou non l’option. À ce compte là, autant commenter le
\usepackagepandoc.# Le 14 février 2015 à 17:36, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Oui, c’est vrai, autant commenter la ligne !
# Le 18 février 2015 à 16:55, par Celano En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Merci pour cet article. Je m’étais pris la tête dans la doc anglophone de pandoc sans être vraiment convaincu du peu que j’avais réussi à en extraire. Le gros souci qui se posait, c’était la fameuse bibliographie. Mais maintenant j’ai appris comment faire, et ce en quelques lignes françaises seulement !
Ce qui m’intéresse beaucoup, c’est l’exportation epub pour pouvoir travailler sur ma liseuse sans imprimer chaque jour mes écrits. Je viens de faire un test rapide, ça a l’air de marcher, à quelques détails près (numérotation des nbp recommence régulièrement à 1 et autres petits détails).
Encore merci !
# Le 20 février 2015 à 12:06, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
La documentation est en effet un peu touffue ! Mais pandoc marche bien dans l’ensemble, et permet d’économiser beaucoup de temps. Pour réaliser un pdf dans un format bien lisible sur une liseuse, il y a aussi ceci (que je n’ai pas testé) : http://ctan.org/tex-archive/macros/latex/contrib/ebook
# Le 26 février 2015 à 08:49, par Stéphane Partiot En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Merci beaucoup pour ces explications. Elles s’avèrent fort utiles, et permettent de répondre aux demandes spécifiques des revues. Je profite de ce message pour vous remercier de toutes les ressources que vous mettez à disposition sur ce site ! Je vous lis avec attention.
# Le 27 février 2015 à 13:13, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
De rien. Pour le coup cet article n’est pas de l’auteur principal du site. Et lui a été aussi très utile ! Merci Robert.
# Le 20 mars 2015 à 14:31, par Fred02840 En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Bonjour,
Je ne vois pas bien l’intérêt qu’il y a à exporter un fichier .tex vers LibreOffice (par exemple). On a une mise en page parfaite avec LaTeX : pourquoi chercher à obtenir un document final de moindre qualité ? À l’inverse, il existe des extensions qui permettent de convertir un fichier LibreOffice en .tex. On peut préparer un tableau complexe, par exemple, tout en voyant ce que l’on fait. Mais le résultat final n’est pas forcément à la hauteur des espérances : il faut revérifier le code.
Merci de votre réponse, Fred02840
# Le 20 mars 2015 à 14:42, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
il n’y a en soit aucun intérêt. Mais dans nos domaines, il arrive bien souvent que les éditeurs refusent de travailler avec du tex et veulent refaire toute la mise en page avec un logiciel de PAO depuis un document Libroffice. C’est d’ailleurs expliqué en début d’article.
# Le 20 mars 2015 à 14:48, par celano En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Et puis rappelons-le : dans les SHS plus que dans d’autres domaines, l’ouverture d’esprit pour utiliser latex n’est pas encore au rendez-vous. Quand on bosse sa thèse comme moi avec une directrice qui ne veut pas entendre parler de latex, on fait quoi ? Soit on la rédige en open office, soit on la rédige en latex et on exporte, quite à remanier un peu le fichier ensuite. Vaste sujet... Enfin, si on conçoit dès le départ un fichier tex en vue de l’exporter par la suite, ça permet de faire une double édition, numérique (epub) et papier (latex-pdf)
# Le 20 mars 2015 à 14:56, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
@celano : elle accepte même pas d’annoter un PDF ?
# Le 20 mars 2015 à 15:04, par celano En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Hum... Non, elle ne veut pas annoter un pdf. Je trouve que ce sont les limites de l’enseignement supérieur en France. J’imprime à chaque fois, et elle corrige à la main. Résultat : elle ne corrige toujours pas les sources, contrairement à ce qu’elle espérait faire avec word, mais elle corrige un document qui est figé (pdf ou papier, il ne peut plus être modifié comme une source).
Pour rire un peu : un jour je lui ai envoyé le fichier source tex pour correction, vu qu’elle ne voulait pas annoter un pdf. Elle m’a renvoyé ses corrections en word en ayant enlevé tous les codes latex ! Qu’est-ce qu’elle a dû en baver pour faire ce travail ingrat.
La Recherche en France... Ça se passe comment ailleurs ?
# Le 20 mars 2015 à 15:07, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
a mon sens ce n’est pas plus mal que le directeur/la directrice ne corrige pas directement le texte, ca permet de s’assurer que cela reste le travail de la doctorante / du doctorant. Je crois qu’ailleurs ce n’est pas mieux, cela dépend vraiment des personnes....
# Le 20 mars 2015 à 15:49, par Fred02840 En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
« mais l’éditeur réclame un fichier dans un format de traitement de texte, avec une bibliographie ou bien une liste des références à la fin ». Il me suffisait de lire correctement l’introduction, en effet. Toutes mes excuses…
# Le 21 mars 2015 à 10:40, par Stéphane P. En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Celano : oui, c’est une question importante que je me pose également.
En même temps, je comprends parfaitement les personnes concernées qui n’ont pas forcément le temps d’apprendre LaTeX pour un ou deux étudiants tout au plus. L’usage demeure encore marginal dans nos champs de recherche, mais grâce aux manuels qui fleurissent et notamment à ce site, on peut espérer que s’étoffent les rangs des latexiens s’étoffent, au-delà de la communauté originale, celle des sciences exactes. Et que l’on abandonne par la même occasion des outils comme Zotero, qui ne sont à mon humble avis que de maigres expédients.
Il faut dire enfin que la correction sur source n’a rien d’évident, même pour qui connaît des éléments de Latex. Non, ce qu’il faut, c’est soit améliorer les possibilités pour annoter un pdf. : pour l’instant, elles demeurent relativement peu pratiques (le meilleur outil que j’ai pu tester est Skim). Soit — et c’est sans doute le plus utile — améliorer les outils de conversions de latex vers .odt ou mieux vers XML, ce qui permettrait ensuite d’obtenir de nombreux formats, .odt et notamment EPUB. Le présent article fournit un certains nombre d’éléments... Il s’agirait de pouvoir approfondir cela. Markdown peut aussi être une piste, mais je ne sais pas grand chose de ce langage sinon qu’il est fort à la mode !
# Le 21 mars 2015 à 10:42, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
markdown fonctionne pour des textes simples, mais pas pour des textes avec une vrai biblio et un apparat de notes...
# Le 21 mars 2015 à 11:03, par Stéphane P. En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
D’accord. En effet. Donc, on oublie.
Dans ce cas, le mieux paraît d’améliorer les procédures de transfert pour l’export final en XML ou ODT, dans la perspective d’un envoi à l’éditeur. Et également pour pouvoir profiter des outils de correction de Word. Et enfin pour l’export en EPUB...
Ce n’est malgré tout pas si simple ! Mais il y a un réel besoin.
Il y a aussi Overleaf qui propose une vue simplifiée de latex, à la LyX...
# Le 21 mars 2015 à 11:54, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Le débat est intéressant !
Pour la correction des épreuves, j’utilise personnellement xournal qui me permet très facilement de les annoter soit au clavier, soit à la main à l’aide d’une tablette graphique. Et c’est aussi rapide que le travail sur papier ! Je demande simplement aux étudiants de laisser une marge suffisante. Par principe, je n’interviens pas dans leur texte. Je suggère seulement des corrections ou des nouvelles pistes.
Pour la remise aux éditeurs, c’est une autre affaire. Une idée pourrait être de créer des gabarits sous la forme de packages (mieux) ou de classes de documents (moins bien à mon avis), maison d’édition par maison d’édition, et collection par collection.
Puisqu’on fait de toute façon le boulot, autant le faire jusqu’au bout, plutôt que faire un travail de déconstruction d’un document abouti.
Ce n’est qu’une idée en passant. Elle ne vaut que pour un document long, et non pour un simple article dans un volume collectif. Dans ce dernier cas, on peut se contenter de pandoc à mon avis.
# Le 21 mars 2015 à 11:58, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Une autre idée pour donner du traitement de texte aux directeurs récalcitrants : compiler le document, et faire un banal « pdftotext », puis ouvrir le ficher .txt produit dans un traitement de texte.
Seul problème : « pdftotex » produit un fichier dans lequel chaque ligne se termine par un hard wrap. Avantage cependant : la numérotation est conservée.
# Le 21 mars 2015 à 12:05, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
quid des notes de bas de page dans ce cas ?
# Le 21 mars 2015 à 12:58, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
On les retrouve au bas des « pages », mais en tant que texte non formaté, comme si on reprenait toute la page par copier-coller. On trouve même toutes les informations qui sont dans les pieds de page, comme par exemple le numéro de la page en cours, de cette façon :
Cela marche très bien. Sauf pour les langues écrites de droite à gauche avec des glyphes complexes comme l’arabe.
# Le 21 mars 2015 à 13:57, par Celano En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Passionnants échanges !
@StéphaneP : markdown est très pratique. Seul inconvénient : les citations... Honnêtement, j’ai beaucoup espéré en markdown : dokuwiki (super moteur de wiki très simple) a une extension pour écrire directement en markdown. J’espérais pouvoir travailler à plusieurs sur un texte directement sur le wiki et ainsi tirer tous les avantages du wiki. Pour une édition papier fiable, exporter ensuite le travail en markdown du wiki vers latex avec pandoc etc. Seulement, pour faire des citations bibliographiques en note, je crois que c’est possible mais pas très convaincant. Mais markdown reste selon moi le plus universel. À venir ?
@Robert : je crois que ce procédé (pdftotext) ne permet pas de garder les mises-en-sens (pour ne pas dire mises-en-forme), italique, gras etc. C’est un paramètre qui manque quand même, parce que même si latex est utile pour séparer le fonds et la forme, à la correction, c’est important qu’il y ait un minimum de mise-en-forme, sans quoi la correction est peu efficace à mon sens.
Merci pour ces témoignages et idées.
# Le 21 mars 2015 à 15:19, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En effet, pdftotext ne conserve que le texte, sans les attributs de mise en forme. Si le texte n’est pas long, ce n’est pas un inconvénient.
Si le texte est long, on peut songer à rediriger les commandes LaTeX avant la compilation. Par exemple :
donnera, après compilation, les mots à mettre en valeur entre doubles paires de crochets droits. Ensuite, on applique une macro pour avoir le résultat voulu dans le traitement de texte.
Tout cela est un peu long et maladroit. Tout dépend en fait des contraintes. Si on est confronté à un directeur qui ne veut pas entendre parler de LaTeX, on peut avoir intérêt à passer un peu de temps à construire un modèle de conversion. Mais il ne faut pas aller au-delà du minimum requis par le directeur.
Pour les éditeurs, c’est une autre histoire. L’idée de packages produisant une mise en page ready to print permet de leur faire accepter le dispositif. Pas mal d’éditeurs en proposent d’ailleurs à leurs auteurs.
# Le 23 mars 2015 à 13:12, par Stéphane P. En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Bonjour,
Merci pour ces réponses. Xournal — ou un équivalent tel que Notelab — paraît bien, notamment pour un travail avec tablette graphique ! Je n’en ai pas pour ma part, mais j’envisagerai peut-être d’en faire l’acquisition dans la mesure où je vois là une application concrète ! Il en existe de souples, qui peuvent donc se transporter facilement, et qui ont aussi l’avantage d’être bon marché (40 euros environ). Je ne sais pas ce qu’elles valent, mais ça paraît tentant. L’annotation de PDF (type Skim) sans une telle tablette paraît quand même assez contraignante — surtout si on la compare au "suivi des modifications" que propose Word, et qui permet en un clic de valider une modifications.
Je ne sais pas comment faire pour que le texte des paragraphes soit automatiquement justifié... etc. Il y aurait un ensemble de macros à mettre en œuvre pour automatiser la phase de post-traitement. On pourrait d’ailleurs regrouper tout ça dans un plugin.
Bref. J’ai enfin pu mettre en application ces consignes. Pandoc apparaît bien comme la solution la plus efficace, et celle qu’il faut privilégier. J’ai particulièrement été convaincu par les styles qui sont bien respectés. Par ailleurs, l’outil est activement développé. L’on peut donc espérer qu’il soit promis à un avenir durable.
Mais pour l’instant, je reste bloqué : les notes de bas de page sont vides dans le fichier .odt final... Je ne parviens pas à voir apparaître la moindre référence. Si quelqu’un a une idée du pourquoi du comment... Je vais continuer à chercher de mon côté. Mais je ne doute pas que je pourrai résoudre cela puisque ça marche pour vous !
Je suis certain que le développement et plus encore la simplification de ces procédure ne pourront que bénéficier à LaTeX, en lui permettant de dialoguer facilement avec d’autres formats que je qualifierais de moins élaborés, en le sortant ainsi de son « splendide isolement ».
# Le 23 mars 2015 à 13:18, par Stéphane P. En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
PS : c’est pour ça que, contrairement à vous Robert, je reste dubitatif quant à la conception de packages par éditeur. L’hégémonie des éditeurs WYSIWYG ne me paraît pas pouvoir être remise en cause rapidement, sinon chez des éditeurs en sciences exactes très spécialisés. Et il y aura toujours quelqu’un dans la chaîne de traitement qui ne maîtrisera pas la chose. Ou bien peut-être que je me trompe.
Si LaTeX permet en un clic de générer du PDF impeccable, mais aussi du Word aussi net que possible, il n’y aura plus grand chose à faire. Avec pandoc, on n’en est plus si loin. On en est même très proches.
# Le 24 mars 2015 à 11:48, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
@Stéphane P. En ce moment même, je suis en train de relire et d’annoter un pdf d’environ 150 pages à l’aide de xournal et de ma tablette. Parfois, j’écris à la main, parfois j’insère du texte saisi au clavier, cela dépend.
Pour la justification des paragraphes dans le fichier odt, j’interviens dans le style de paragraphe par défaut. Mais il est possible de demander à pandoc d’utiliser une feuille de style que l’on a préparée à l’avance. Ce pourrait être l’occasion d’un complément à cet article.
Avez-vous essayé de compiler les documents fournis en attachement à cet article ?
# Le 24 mars 2015 à 11:52, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
@Stéphane P. Mon idée était de fournir aux éditeurs un fichier pdf final répondant parfaitement aux normes de mise en page de l’éditeur. Mais pour éviter d’imposer cela aux éditeurs, le mieux est de leur demander leur avis avant de faire le package.
# Le 12 avril 2015 à 18:01, par Stéphane P. En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
@ Robert Alessi
Je suis enfin parvenu à faire fonctionner pandoc. J’avais quelques clefs un peu barbares dans mon fichier .bib (des points d’interrogation qui passaient pour LaTeX mais pas pour Pandoc).
Le résultat est donc maintenant presque parfait. Je vais me pencher sur les feuilles de style pandoc pour tenter d’obtenir quelque chose d’impeccable en une ligne de commande. Mais encore faut-il que de telles feuilles de style restent compatible en cas de nouvelle version de pandoc.
Pour le CSL, j’ai choisi celui intitulé EHESS-histoire que j’ai modifié de manière très marginale. Il me semble être le plus proche des normes bibliographiques françaises.
Merci encore pour tout cela, cher Monsieur !
# Le 12 avril 2015 à 18:05, par Stéphane P. En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
J’ajoute que — cerise sur le gâteau virtuel — cela permet également de générer des .epub impeccables (avec des notes placées en fin d’ebook et correctement liées). Ce qui peut s’avérer très utile pour les possesseurs de liseuses électroniques... ou pour les e-éditeurs en herbe.
# Le 12 avril 2015 à 18:18, par Stéphane P. En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
(Désolé pour les messages multiples).
Il reste encore un point qui me taraude : j’utilise \enquote{} pour mes citations et je ne parviens pas à obtenir de guillemets français ! Votre exemple propose de faire rechercher/remplacer mais je trouve dommage qu’il faille abandonner dans ce cas \enquote{} qui est bien pratique... Je vais y réfléchir.
Sinon, il faut voir encore une fois je suppose du côté des templates pandoc.
# Le 13 avril 2015 à 18:54, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Pour des commandes telles que
\enquote{}, on peut toujours les rediriger comme ceci :Cela donnera des guillemets français, mais sans rendre disponibles toutes les fonctionnalités du package csquotes.
# Le 7 novembre 2015 à 11:00, par Eric En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Encore merci pour ces précisions. Je trouve que nos convertisseurs et fichiers de style sont encore bien imparfaits. Pour info, j’utilise latex et bibtex (et donc pas xelatex ni biblatex) Par exemple les .csl à la française n’intègrent pas les URL de la bibliographie (ex. : PUR). La csl de harvard le fait très bien. Ensuite pandoc gère de façon bizarre les appels biblio : quand j’attends un « l’importance de la matérialité (Dagognet, 1989) » j’obtiens un « l’importance de la matérialité Dagognet (1989) » Et c’est pareil quand je décompresse l’odt.
Idée de solutions pour l’appel biblio : Dans l’odt lu sous libreoffice comme dans le content.xml, j’ai un blanc insécable avant le nom de l’auteur. Donc c’est gérable mais pas fabuleux. (La sortie html est aussi mal présentée mais au moins affiche des balises qui permettent de retravailler automatiquement la chose : span class="citation" Dagognet (1989) finduspan. Je peux donc faire un tex vers html vers odt).
D’où quelques questions 1. Avez-vous des conseils à me donner ? Il est possible que j’oublie des paramètres. 2. Y a t il une version francisée de harvard.csl ou sinon qui ne supprime pas les URL de la biblio finale ? 3. Quand vous devez convertir un .tex en odt ou docx, réussissez-vous à le faire en une seule passe avec pandoc, ou devez vous systématiquement fignoler les choses à la main ? Par exemple, pandoc ne gère pas mes images pdf (mais traduit bien les png).
Merci d’avance Cordialement Eric
PS : texte un peu modifié car le site me dit "Il n’est pas permis d’insérer des images ni d’utiliser les attributs html class ou style"
# Le 7 novembre 2015 à 11:07, par Eric En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
PS : je réalise que le blanc insécable apparaît parce que je l’ai moi même glissé dans le .tex (tilde\cite{xxx}). Pour autant, mes 3 questions valent toujours.
Sourires et cordialement Eric
# Le 8 novembre 2015 à 12:05, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Bonjour Éric,
Le premier conseil que je donnerais serait de passer à biblatex !
Cela dit, à ma connaissance, il n’y a pas de version francisée de harvard.csl. Le mieux est de partir du site "https://www.zotero.org/styles« , puis de choisir le filtre »author-date« , et enfin de chercher sur la page le mot »french« : actuellement, il y a 28 résultats. Je viens de faire un petit essai : le style »institut-national-de-la-recherche-scientifique-sciences-sociales.csl" me semble prendre en compte les url de façon correcte. Autre possibilité : éditer le fichier csl harvard et le franciser. C’est du xml tout simple.
Pour les paramètres, ceci marche très bien (exemple avec xelatex/biblatex) : pandoc —filter pandoc-citeproc —csl=fichier.csl —bibliography=fichier.bib —biblatex —latex-engine=xelatex fichier.tex -o fichier.odt
Je ne savais pas que pandoc ignorait les images pdf. Mais à cette réserve près, oui, la ligne ci-dessus assure la conversion en une seule passe.
# Le 9 novembre 2015 à 14:58, par Eric En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Bonjour Robert
Merci pour ces réponses. Je veux bien passer à biblatex mais la chose n’a pas l’air aisée. Il y a des confusions avec biber, bibtex8, etc. Du moins de mon point de vue. J’ai commencé à rectifier des .csl, effectivement ce n’est pas difficile. Et en tout humour, vous n’avez pas répondu à ma question avec l’utilisation latex+bibtex. Avez-vous essayé et vérifié que les appels bibliographiques sont mal convertis par pandoc avec ces deux instruments ? Bien cordialement Eric
# Le 9 novembre 2015 à 15:08, par Maïeul En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
pour répondre sur le point biblatex/biber
biblatex2 est prévu pour fonctionner nativement avec biber. Tout les autres scripts sont obsolètes et manquent de souplesse. Donc bien qu’on puisse migrer à biblatex en restant en bibtex, il vaut mieux utiliser biblatex + biber.
# Le 9 novembre 2015 à 15:21, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En effet, je reconnais avoir biaisé !
J’ai donc repris le même fichier avec pdflatex+bibtex. Mais je m’associe à ce que Maïeul vient d’écrire : il faut passer à biblatex+biber !
Ligne de commande :
Et dans le fichier .odt, j’ai ceci :
Il me semble donc que la conversion est correcte, n’est-ce pas ? Voici ce que j’ai mis dans le fichier .tex :
# Le 1er décembre 2015 à 00:01, par Guichard En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Désolé pour le temps pris à répondre. En deux points : 1. je suis d’accord avec la proposition « passer à biblatex+biber ! ». On y réfléchira ensemble, et avec votre aide : rien d’élémentaire ne m’apparaît, dans ma courte review du web. 2. Nous sommes d’accord sur le résultat produit par pandoc. Mais je ne veux pas un « Je me cite : Alessi (2010, 65) », mais un « comme il a été prouvé [Alessi, 2010], Galien est un piètre médecin ». En bref, je désirerais un emballage de l’appel biblio entre crochets (ou parenthèses), comme le font la majorité des outils biblio à partir de pdflatex. Nous sommes bien d’accord : pandoc fonctionne avec votre exemple exactement comme sur ma machine. Comment donc obtenir ce « [appelbiblio] » qui me manque tant ? Sourires et bien cordialement. EG
# Le 5 décembre 2015 à 07:53, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Je tarde aussi un peu à répondre, mais c’est avec plaisir que je le fais !
En ce qui concerne biblatex+biber, c’est entendu. Le mieux sera si vous en êtes d’accord de m’écrire à mon adresse personnelle. Je vous invite aussi à vous référer aux très nombreux articles que Maïeul a consacrés à ce sujet sur ce site.
Pour les crochets droits à la place des parenthèses : facile ! Il suffit d’éditer le fichier de style .cls que vous avez choisi d’utiliser, et de faire une recherche/remplacement des attributs comme suit :
Puis de recompiler. Et le tour est joué !
# Le 5 décembre 2015 à 07:54, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Et comment ça, Galien est un piètre médecin ? ;)
# Le 23 mars 2017 à 16:36, par Jean-Michel En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Bonjour Je n’arrive toujours pas à obtenir la bibliographie avec pandoc. J’ai testé avec les fichiers de l’archive zip et les commandes pandoc de ce post. J’obtiens bien article.odt avec le grec, l’arabe, les images, mais il n’y a rien sous le titre « bibliographie » à la fin. Comme si ma version de pandoc (pandoc 1.16.0.2, sous Ubuntu 16.04.2 LTS) ne voulait rien savoir de la bibliographie. Et j’ai eu beau chercher sur le net, je n’ai rien trouvé qui puisse m’aider. Du coup, sauf dans les cas où je suis certain que je n’aurai pas de conversion à faire, je suis contraint d’abandonner (Xe)LaTeX, ce qui est bien dommage, pour revenir à un LaTeX classique, compilé avec latexpdf et convertible avec latex2rtf. Suis-je le seul à rencontrer ce problème avec pandoc ?
# Le 23 mars 2017 à 16:41, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Vérifiez que votre installation est complète. Vous devriez avoir :
# Le 23 mars 2017 à 18:02, par Eric Guichard En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Vous trouverez à l’URL http://barthes.enssib.fr/cours/informatique-pour-litteraires/ un programme perl (pgmpandoc.pl) qui permet de convertir automatiquement en le format désiré un fichier .tex C’est bien parce que pandoc est assez délicat que j’ai fait ce programme, dont je me sers fréquemment. Je tiens à votre disposition un fichier .csl qui fait les choses d’une façon satisfaisante (et prochainement en ligne). Sinon, Robert, a raison. If faut disposer de pandoc-citeproc Bien cordialement Eric
# Le 23 mars 2017 à 18:12, par Jean-Michel En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Merci. De fait, pandoc-citeproc n’était pas installé. Mais même après installation la commande avec le choix par défaut du style Chicago author-date ne produit ni bibliographie ni référence bibliographique. Il a fallu pour que ça fonctionne que j’utilise la commande complète pandoc —filter pandoc-citeproc —csl=harvard-kings-college-london.csl \
— bibliography=« bibliographie.bib » —biblatex \
— latex-engine=xelatex article.tex -o article.odt après avoir installé le csl dans le répertoire de travail. Bref, je n’ai pas encore tout compris, mais ça fonctionne désormais au moins comme ça. Le paquet pandoc-crossref n’existe pas dans ubuntu 16.04 et ne semble pas indispensable. Question subsidiaire. Je constate que le .csl et le .bib ne doivent pas nécessairement être placés dans le répertoire de travail. On peut dans la commande préciser le chemin complet vers eux. Mais est-il possible de dire à pandoc une bonne fois pour toutes dans quel répertoire il trouvera ces fichiers (variable d’environnement ou autre) ?
# Le 23 mars 2017 à 19:51, par Robert Alessi En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
En réponse à : Comment convertir un article saisi en .tex vers un traitement de textes
Oui, pandoc-crossref n’est pas requis pour la bibliographie. Quant à indiquer à pandoc où les fichiers de configuration sont placés, je pense que le plus simple est de le programmer dans un script, et donc, puisque cela est déjà fait grâce aux bons soins d’Éric, adapter les paramètres dans le fichier perl une fois pour toutes. Merci à lui ! J’irai voir dès que possible.